On this page
- Introduction
- Mental models
- Push-based GitOps
- Push-based basic pseudo-GitOps
- Push-based pseudo-GitOps
- Push-based GitOps
- Pull-based GitOps
- Pull-based GitOps
- Pull-based GitOps Alternative (GitOps Controller Architecture)
- Building on our previous work
- Understanding the differences
- Some Pull-based Tools:
- Getting started with GitOps
- Choosing the right approach
- Conclusion
Support this blog
If you find this content useful, consider supporting the blog.
Introduction#
In this article we will explore GitOps and what it means, how it is used and why it is so effective in many large organizations.
GitOps as the name suggests is a way to manage operations. Operations is often the name given to the management of software and infrastructure required for it to function and be delivered and deployed (SDLC). But why Git? Well, turns out that Git is the perfect match to track changes in code and also in infrastructure and related resources.
Some of the benefits are:
- Traceability: Every change is logged with author, timestamp and commit message
- Integrity: Git's cryptographic hashing ensures the integrity of your infrastructure definitions
- Easier collaboration: Pull requests, reviews, and branching strategies enable better teamwork
- Adaptability: Works with different infrastructures, platforms, and tools
Among other benefits, but it doesn't come for free. It also has its challenges and things depend a lot on personal preferences and organizational requirements.
Let's explore what this means in practice.
Mental models#
There are basically two mental models in GitOps: push-based and pull-based. You might be thinking this is simple enough, but the end result can change substantially based on which approach you pick.
Note: imagine we have a Kubernetes cluster and some repos with GitHub Actions as CI/CD.
Push-based GitOps#
In a push-based approach, your workflows will trigger a mechanism to update the application (environment), whether in containers or somewhere in a data center. Basically, after you have your artifact built (docker image, tar file, package, jar file, whatever it might be), you need to push that change or trigger the workflow that will push that change so the newer version of the application starts to run and replaces the old version, while this may sounds super simple there are multiple ways of achieving it, let's explore these 3 initial scenarios:
Push-based basic pseudo-GitOps#
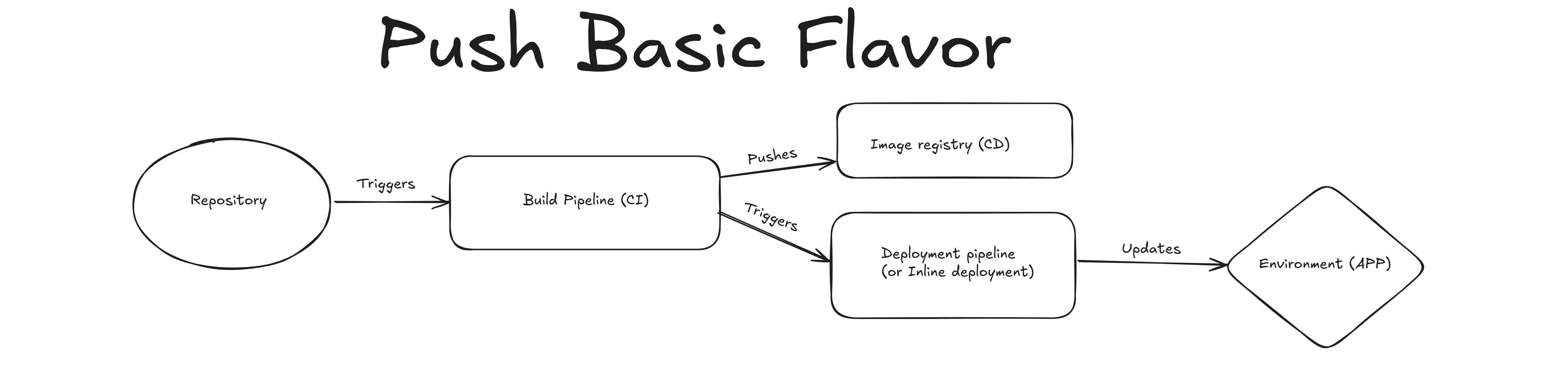
A change in the repository triggers a build in CI, which is then pushed to an image registry, the next step in the pipeline is to trigger the update for the environment.
Imagine helm is being used to deploy the application so CI would have something like:
helm upgrade --install my-release -n my-namespace --set='image.tag'="${{ github.sha }}"
Push-based pseudo-GitOps#
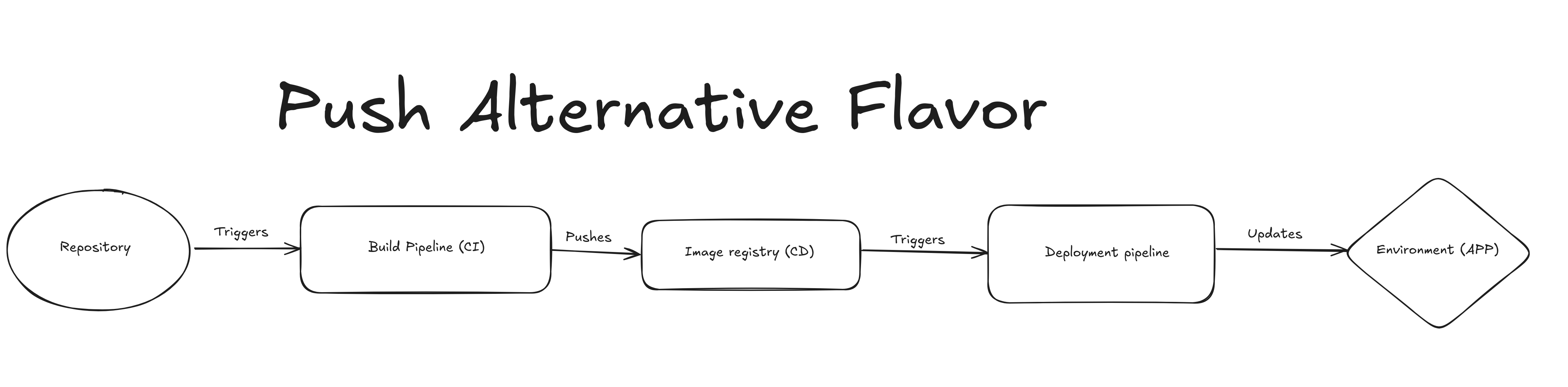
The next iteration is similar but the deployment gets triggered by the image being pushed to the registry.
Note: these two are pseudo GitOps because git is almost the source of truth, we are missing the manifests repository.
Push-based GitOps#
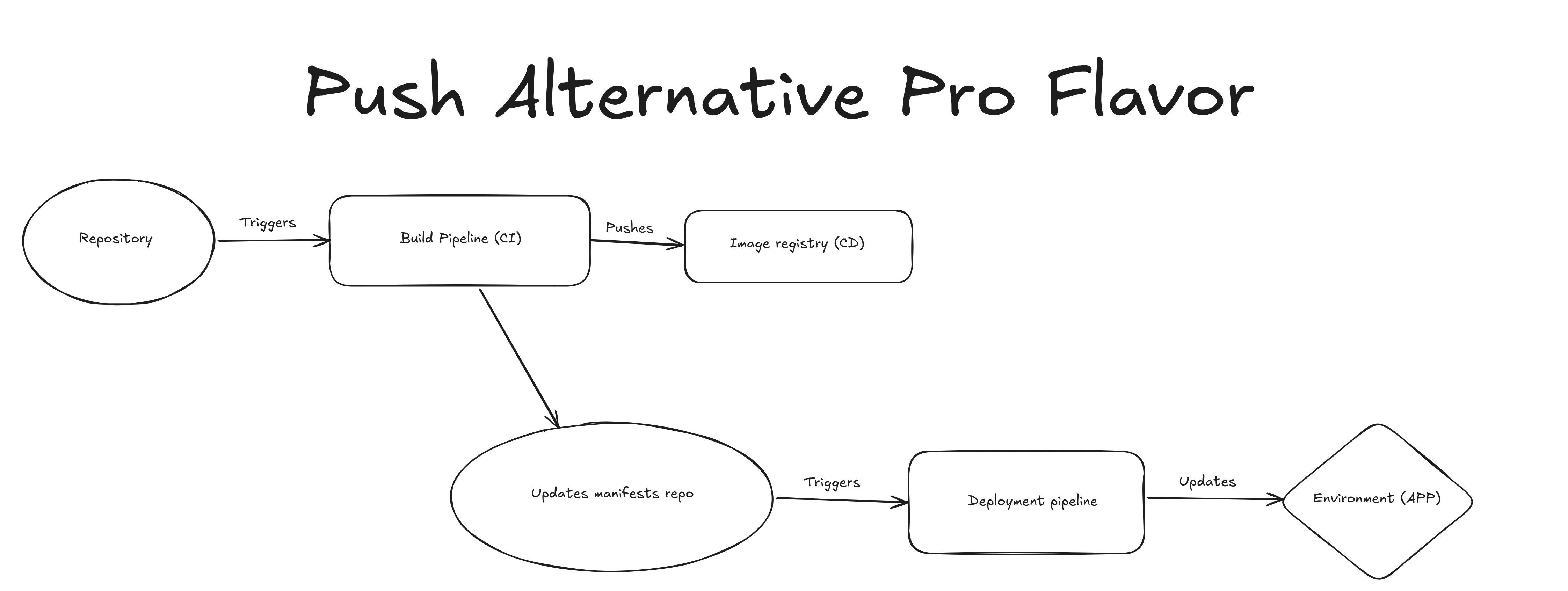
This is the first true GitOps approach where we have an extra repository called "app-manifests" or also known as the environment repository, that's where the SHA of the code repository gets stored, and then a deployment pipeline gets triggered by that change.
Simple enough, right? This works great in small environments where there are not a lot of dependencies. However, as your application starts to grow and you have more and more services, dependencies start to form and also bring complexity to this scenario. While it is possible to handle complex scenarios with this approach, it can get more cumbersome over time.
There is another alternative flavor for the push-based model, and that's using webhooks. Basically, what would trigger an action in another system, for example GitHub can trigger an http request to your defined endpoint when there are changes in your repository, then you can parse the payload and do some extra processing or trigger a remote build, and so on, either way you are triggering another workflow or sending an http to a custom system this is still part of the push-based model.
The main benefit of this approach is the flexibility given by the code at the receiving endpoint to make all the decisions you need, plus the speed, in most cases webhooks are received immediately. There could be issues as well, like delays or missing messages which would translate to missing builds or deployments.
So now, let's explore the pull-based mechanism.
Pull-based GitOps#
So what about pull-based GitOps? "Pull" means that there is a mechanism checking your resources externally (there could be hybrid mechanisms using webhooks for example). Imagine that you have a process checking your repository every few minutes to discover changes and trigger builds, deploys, etc.
Pull-based GitOps#
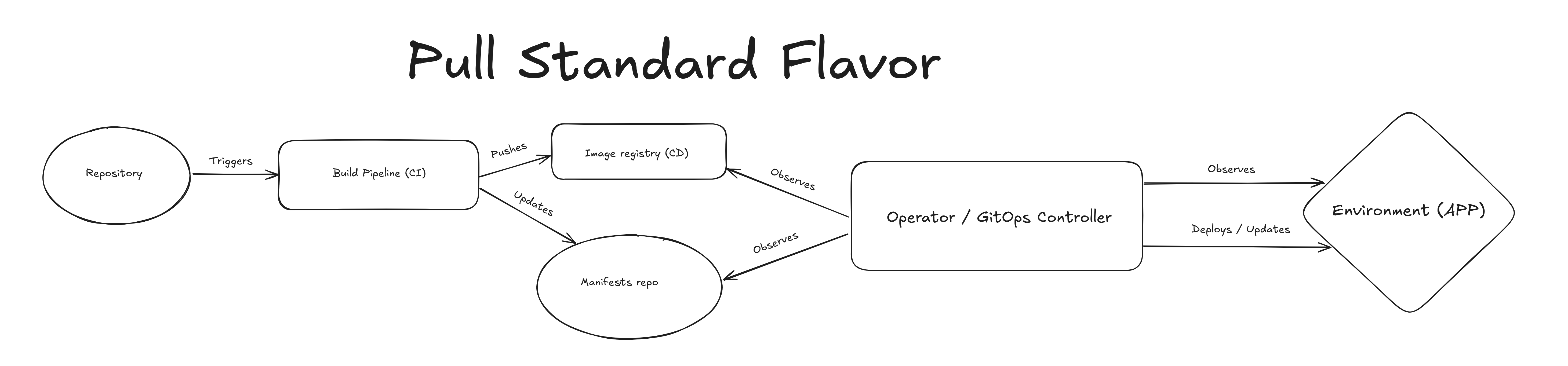 In this scenario the first part is still the same, but our CI has the reponsibility of updating the manifest or
environment repository, our controller then will be watching changes in both the repository and the registry for changes
as well as the infrastructure to keep things in sync, in my opinion that puts just too many reponsibilities in the
controller, but this way you could handle many more complex scenarios straight from your preferred language.
In this scenario the first part is still the same, but our CI has the reponsibility of updating the manifest or
environment repository, our controller then will be watching changes in both the repository and the registry for changes
as well as the infrastructure to keep things in sync, in my opinion that puts just too many reponsibilities in the
controller, but this way you could handle many more complex scenarios straight from your preferred language.
Pull-based GitOps Alternative (GitOps Controller Architecture)#
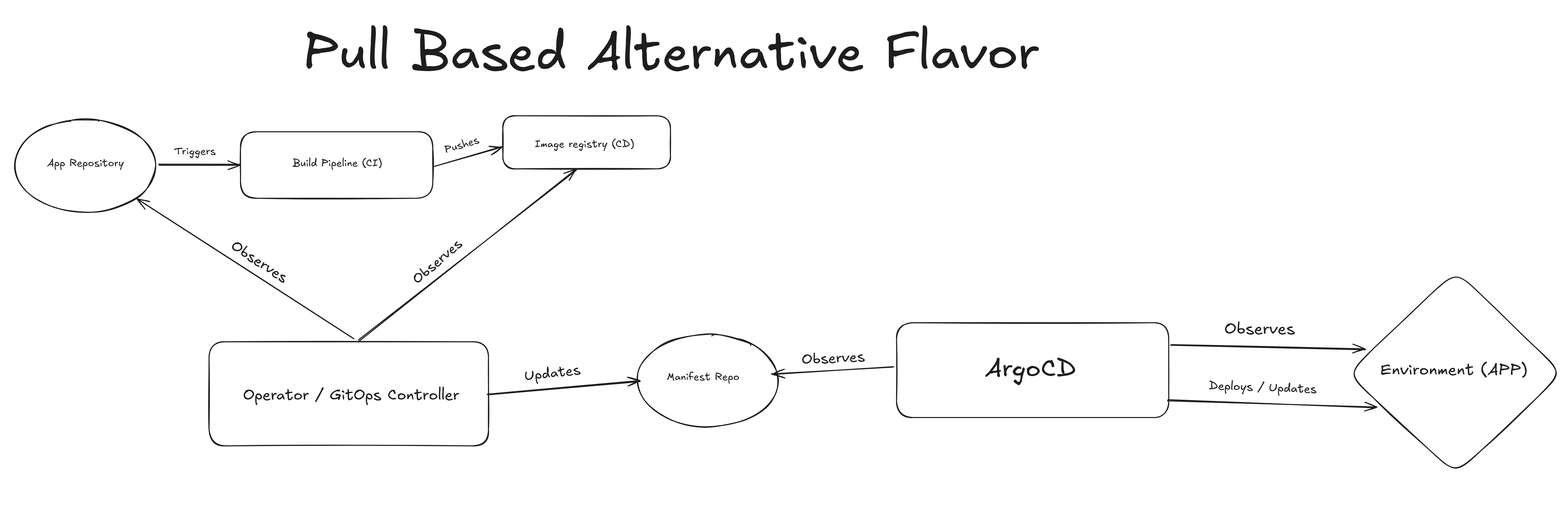 You might have read the last article about the subject GitOps Operator,
if not maybe it is a good time to check it out, but basically in this case the controller is in charge of monitoring git
and the image registry for changes (validate that there is a new image for a new SHA) and updating the manifests or
environment repository, then we have ArgoCD (it could be flux or whatever you prefer) watching the manifests repository
and applying changes to the environment.
You might have read the last article about the subject GitOps Operator,
if not maybe it is a good time to check it out, but basically in this case the controller is in charge of monitoring git
and the image registry for changes (validate that there is a new image for a new SHA) and updating the manifests or
environment repository, then we have ArgoCD (it could be flux or whatever you prefer) watching the manifests repository
and applying changes to the environment.
Building on our previous work#
In our previous article, we built a custom GitOps operator in Rust that follows the pull-based model. The operator watches Kubernetes deployments with specific annotations and automatically updates manifests in a Git repository when a new application version is detected.
This demonstrates a practical implementation of the pull-based GitOps workflow, where:
- Developers push code changes to an application repository
- CI builds and publishes a new container image
- Our operator detects the new version and updates the manifest repository
- ArgoCD deploys the updated manifests to the cluster
This workflow provides complete traceability through Git, automated deployments, and clear separation of concerns between application development and deployment.
Understanding the differences#
| Feature | Push-based | Pull-based |
|---|---|---|
| Trigger mechanism | CI system pushes changes | Controller periodically checks for changes |
| Permissions | CI needs cluster access | Cluster components pull from Git |
| Security boundary | CI system has outbound connection to cluster | Git is the only entry point |
| Complexity | Simpler initial setup | Requires additional controller/operator |
| Audit trail | Git history + CI logs | Git history is the single source of truth |
| Drift detection | Requires additional tooling | Built-in (controller constantly reconciles) |
Some Pull-based Tools:#
- ArgoCD
- Flux CD
- Our custom GitOps Operator,
- Many more.
Getting started with GitOps#
If you're looking to implement GitOps in your organization, here are some steps to get started:
- Choose your model: Decide whether push-based or pull-based makes more sense for your team.
- Select tools: Based on your model, choose the appropriate tools (e.g., ArgoCD for pull-based).
- Structure your repositories: Decide how to organize your code and manifests - single repo or separate repos.
- Start small: Begin with a simple application and expand as you gain confidence.
- Establish best practices: Create guidelines for commits, reviews, and approvals.
Choosing the right approach#
The approach you choose depends on several factors:
- Team size and structure Smaller teams might prefer push-based for simplicity, while larger organizations with multiple teams benefit from the governance of pull-based.
- Security requirements: If your security team requires strict control over what gets deployed, pull-based provides better isolation.
- Operational maturity: Pull-based approaches enforce more discipline but require more initial investment.
- Deployment frequency: High-frequency deployments might benefit from either approach, depending on your specific requirements.
Conclusion#
GitOps provides a powerful paradigm for managing both applications and infrastructure. Whether you choose a push-based or pull-based approach, the core principle remains the same: Git as the single source of truth.
By adopting GitOps practices, you gain better visibility, reliability, and governance over your deployments. As you've seen in our previous article's implementation, creating custom GitOps tooling is also possible to meet specific requirements.
Remember that there's no one-size-fits-all solution. The best approach depends on your team's needs, skillset, and organizational constraints. Start small, learn from your experiences, and adapt as you go.
If you want to learn more about GitOps I encourage you to read this page and experiment with it yourself.
Hope you found this useful and enjoyed reading it, until next time!
$ Comments
Online: 0Please sign in to be able to write comments.