Hablemos de GitOps
On this page
- Introducción
- Modelos mentales
- GitOps basado en push
- GitOps básico basado en push (pseudo-GitOps)
- Pseudo-GitOps basado en push
- GitOps basado en push
- GitOps basado en pull
- GitOps basado en pull
- GitOps basado en pull alternativo (Arquitectura del Controlador GitOps)
- Continuando con nuestro trabajo anterior
- Entendiendo las diferencias
- Algunas herramientas basadas en Pull:
- Comenzando con GitOps
- Eligiendo el enfoque correcto
- Conclusión
Apoya este blog
Si te resulta util este contenido, considera apoyar el blog.
Introducción#
En este artículo vamos a explorar qué es GitOps, cómo se utiliza y por qué es tan efectivo en muchas organizaciones grandes.
GitOps, como su nombre lo sugiere, es una forma de gestionar operaciones, operaciones es el nombre que se le da habitualmente a la gestión de software e infraestructura necesaria para su funcionamiento (SDLC). ¿Pero por qué Git? Bueno, resulta que Git es la herramienta perfecta para rastrear cambios en el código y también en la infraestructura y recursos relacionados.
Algunos de los beneficios son:
- Trazabilidad: Cada cambio queda registrado con autor, fecha y mensaje de commit
- Integridad: El hashing criptográfico de Git asegura la integridad de las definiciones de infraestructura
- Colaboración más sencilla: Pull requests, revisiones y estrategias de ramificación permiten un mejor trabajo en equipo
- Adaptabilidad: Funciona con diferentes infraestructuras, plataformas y herramientas
Entre otros beneficios, pero no viene gratis. También tiene sus desafíos y las cosas dependen mucho de las preferencias personales y los requisitos organizacionales.
Veamos qué significa esto en la práctica.
Modelos mentales#
Básicamente hay dos modelos mentales en GitOps: basado en push y basado en pull. Quizás estés pensando que esto es bastante simple, pero el resultado final puede cambiar sustancialmente según el enfoque que elijas.
Nota: imaginemos que tenemos un cluster de Kubernetes y algunos repositorios con GitHub Actions como CI/CD.
GitOps basado en push#
En un enfoque basado en push, tus workflows dispararán un mecanismo para actualizar la aplicación (entorno), ya sea en contenedores o en algún lugar de un centro de datos. Básicamente, después de tener tu artefacto construido (imagen de docker, archivo tar, paquete, archivo jar, lo que sea), necesitás pushear ese cambio o disparar el workflow que pusheará ese cambio para que la nueva versión de la aplicación comience a ejecutarse y reemplace la versión anterior. Si bien esto puede sonar super simple, hay múltiples formas de lograrlo, exploremos estos 3 escenarios iniciales:
GitOps básico basado en push (pseudo-GitOps)#
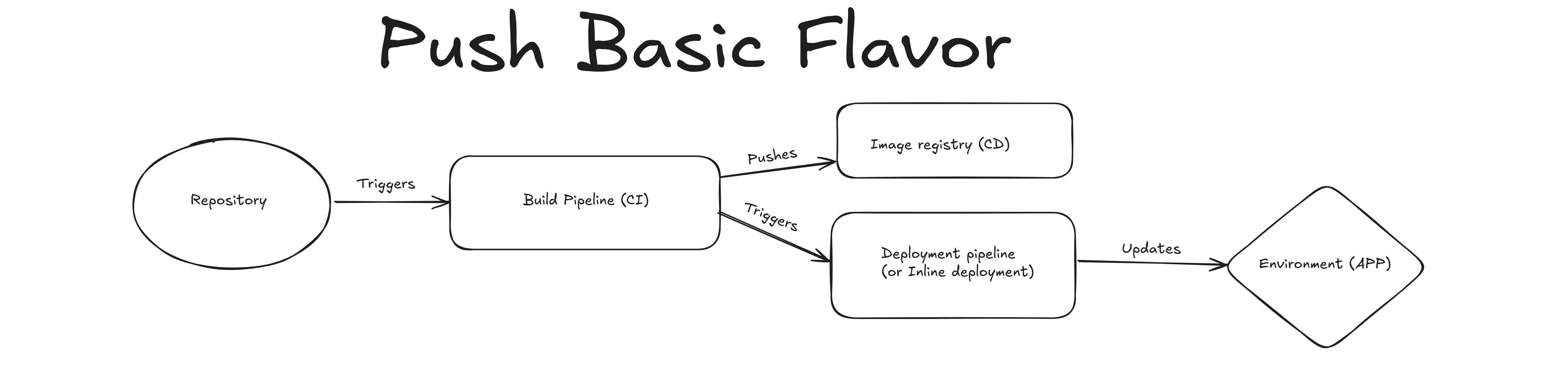
Un cambio en el repositorio dispara una construcción en CI, que luego se pushea a un registro de imágenes. El siguiente paso en el pipeline es disparar la actualización para el entorno.
Imaginate que se está usando Helm para desplegar la aplicación, entonces CI tendría algo como:
helm upgrade --install my-release -n my-namespace --set='image.tag'="${{ github.sha }}"
Pseudo-GitOps basado en push#
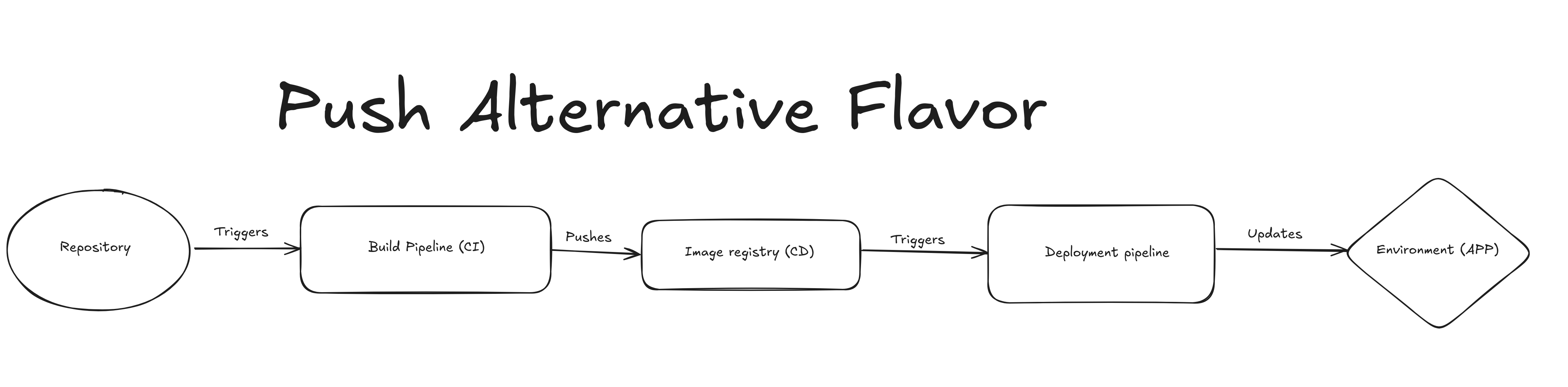
La siguiente iteración es similar, pero el despliegue se dispara por la imagen que se pushea al registro.
Nota: estos dos son pseudo-GitOps porque Git es casi la fuente de verdad todavia nos falta el repositorio del los manifests.
GitOps basado en push#
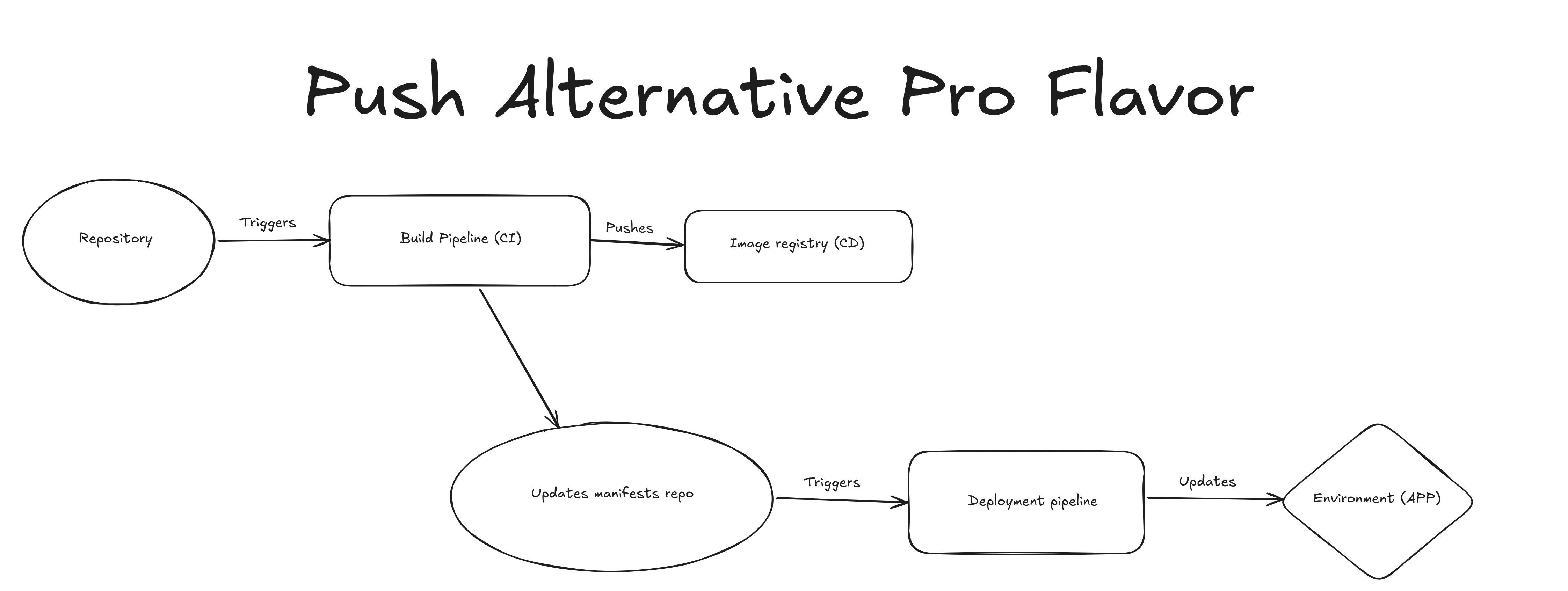
Este es el primer enfoque verdadero de GitOps donde tenemos un repositorio extra llamado "app-manifests" o también conocido como el repositorio de entorno. Ahí es donde se almacena el SHA del repositorio de código, y luego un pipeline de despliegue se dispara por ese cambio.
Bastante simple, ¿no? Esto funciona muy bien en entornos pequeños donde no hay muchas dependencias. Sin embargo, a medida que tu aplicación crece y tenés más y más servicios, las dependencias comienzan a formarse y también traen complejidad a este escenario. Si bien es posible manejar escenarios complejos con este enfoque, puede volverse más engorroso con el tiempo.
Hay otra variante alternativa para el modelo basado en push, y es usando webhooks. Básicamente, lo que dispararía una acción en otro sistema, por ejemplo, GitHub puede disparar una solicitud http a tu endpoint definido cuando hay cambios en tu repositorio, luego podés analizar la carga útil y hacer algún procesamiento adicional o disparar una construcción remota, y así sucesivamente. De cualquier manera, estás disparando otro workflow o enviando una solicitud http a un sistema personalizado, esto sigue siendo parte del modelo basado en push.
El principal beneficio de este enfoque es la flexibilidad que da el código en el endpoint receptor para tomar todas las decisiones que necesitás, además de la velocidad. En la mayoría de los casos, los webhooks se reciben inmediatamente. También podría haber problemas, como retrasos o mensajes perdidos que se traducirían en construcciones o despliegues perdidos.
Así que ahora, exploremos el mecanismo basado en pull.
GitOps basado en pull#
¿Y qué hay del GitOps basado en pull? "Pull" significa que hay un mecanismo que verifica tus recursos externamente (podría haber mecanismos híbridos usando webhooks, por ejemplo). Imaginate que tenés un proceso que verifica tu repositorio cada pocos minutos para descubrir cambios y disparar construcciones, despliegues, etc.
GitOps basado en pull#
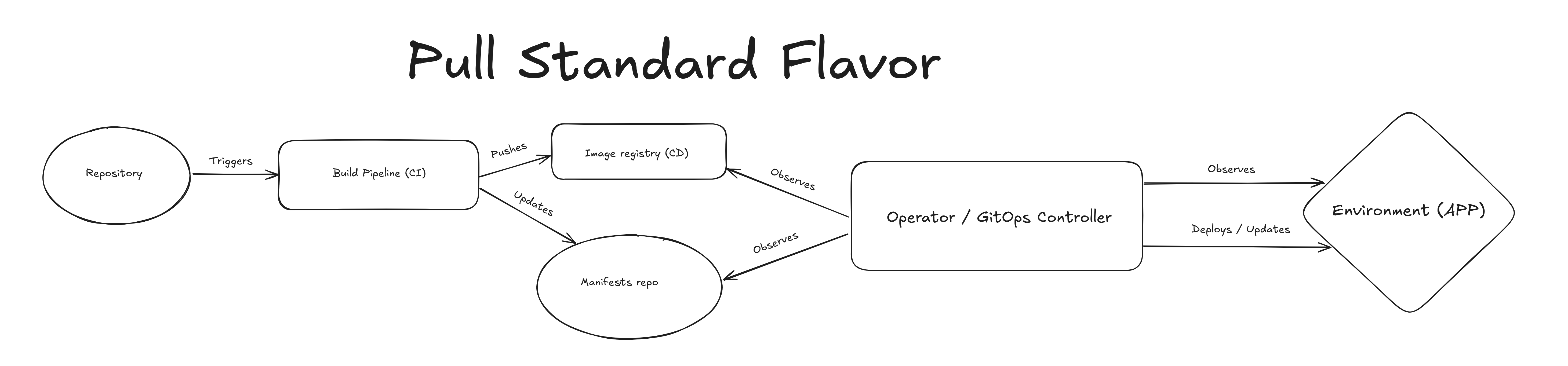 En este escenario, la primera parte sigue siendo la misma, pero nuestro CI tiene la responsabilidad de actualizar el repositorio de manifiestos o entorno. Nuestro controlador luego estará observando los cambios tanto en el repositorio como en el registro para detectar cambios, así como en la infraestructura para mantener las cosas sincronizadas. En mi opinión, esto pone demasiadas responsabilidades en el controlador, pero de esta manera podrías manejar muchos escenarios más complejos directamente desde tu lenguaje preferido.
En este escenario, la primera parte sigue siendo la misma, pero nuestro CI tiene la responsabilidad de actualizar el repositorio de manifiestos o entorno. Nuestro controlador luego estará observando los cambios tanto en el repositorio como en el registro para detectar cambios, así como en la infraestructura para mantener las cosas sincronizadas. En mi opinión, esto pone demasiadas responsabilidades en el controlador, pero de esta manera podrías manejar muchos escenarios más complejos directamente desde tu lenguaje preferido.
GitOps basado en pull alternativo (Arquitectura del Controlador GitOps)#
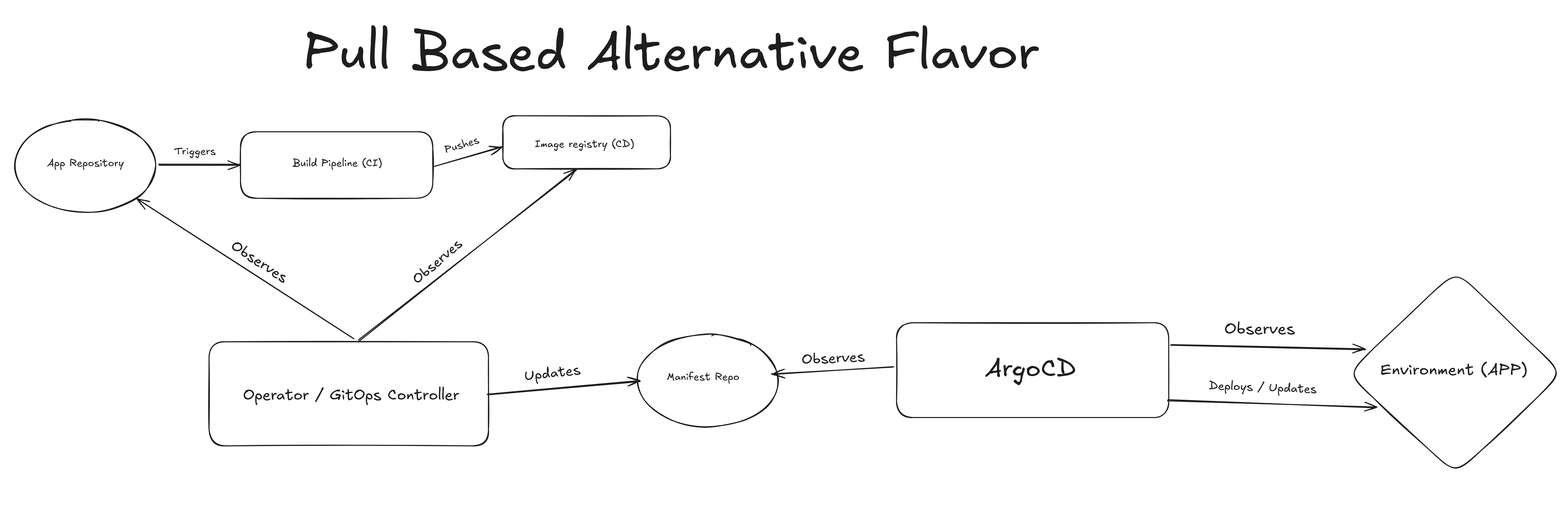 Es posible que hayas leído el último artículo sobre el tema GitOps Operator, si no, tal vez sea un buen momento para revisarlo. Pero básicamente, en este caso, el controlador se encarga de monitorear git y el registro de imágenes para detectar cambios (validar que hay una nueva imagen para un nuevo SHA) y actualizar los manifiestos o el repositorio de entorno. Luego tenemos ArgoCD (podría ser Flux o lo que prefieras) observando el repositorio de manifiestos y aplicando cambios al entorno.
Es posible que hayas leído el último artículo sobre el tema GitOps Operator, si no, tal vez sea un buen momento para revisarlo. Pero básicamente, en este caso, el controlador se encarga de monitorear git y el registro de imágenes para detectar cambios (validar que hay una nueva imagen para un nuevo SHA) y actualizar los manifiestos o el repositorio de entorno. Luego tenemos ArgoCD (podría ser Flux o lo que prefieras) observando el repositorio de manifiestos y aplicando cambios al entorno.
Continuando con nuestro trabajo anterior#
En nuestro artículo anterior, construimos un operador GitOps personalizado en Rust que sigue el modelo basado en pull. El operador observa los despliegues de Kubernetes con anotaciones específicas y actualiza automáticamente los manifiestos en un repositorio Git cuando se detecta una nueva versión de la aplicación.
Esto demuestra una implementación práctica del flujo de trabajo GitOps basado en pull, donde:
- Los desarrolladores pushean cambios de código a un repositorio de aplicación
- CI construye y publica una nueva imagen de contenedor
- Nuestro operador detecta la nueva versión y actualiza el repositorio de manifiestos
- ArgoCD despliega los manifiestos actualizados en el cluster
Este flujo de trabajo proporciona trazabilidad completa a través de Git, despliegues automatizados y una clara separación de preocupaciones entre el desarrollo de aplicaciones y el despliegue.
Entendiendo las diferencias#
| Característica | Basado en Push | Basado en Pull |
|---|---|---|
| Mecanismo de disparo | El sistema CI pushea cambios | El controlador verifica periódicamente los cambios |
| Permisos | CI necesita acceso al cluster | Los componentes del cluster hacen pull desde Git |
| Límite de seguridad | El sistema CI tiene conexión saliente al cluster | Git es el único punto de entrada |
| Complejidad | Configuración inicial más simple | Requiere controlador/operador adicional |
| Auditoría | Historial de Git + logs de CI | El historial de Git es la única fuente de verdad |
| Detección de desviaciones | Requiere herramientas adicionales | Integrado (el controlador reconcilia constantemente) |
Algunas herramientas basadas en Pull:#
- ArgoCD
- Flux CD
- Nuestro GitOps Operator personalizado
- Muchas más.
Comenzando con GitOps#
Si estás pensando en implementar GitOps en tu organización, acá hay algunos pasos para comenzar:
- Elegí tu modelo: Decidí si el enfoque basado en push o pull tiene más sentido para tu equipo.
- Seleccioná herramientas: Basado en tu modelo, elegí las herramientas apropiadas (por ejemplo, ArgoCD para el enfoque basado en pull).
- Estructurá tus repositorios: Decidí cómo organizar tu código y manifiestos - un solo repo o repos separados.
- Empezá de a poco: Comenzá con una aplicación simple y expandite a medida que ganás confianza.
- Establecé mejores prácticas: Creá pautas para commits, revisiones y aprobaciones.
Eligiendo el enfoque correcto#
El enfoque que elijas depende de varios factores:
- Tamaño y estructura del equipo: Los equipos más pequeños podrían preferir el enfoque basado en push por su simplicidad, mientras que las organizaciones más grandes con múltiples equipos se benefician de la gobernanza del enfoque basado en pull.
- Requisitos de seguridad: Si tu equipo de seguridad requiere un control estricto sobre lo que se despliega, el enfoque basado en pull proporciona mejor aislamiento.
- Madurez operativa: Los enfoques basados en pull exigen más disciplina pero requieren una inversión inicial mayor.
- Frecuencia de despliegue: Los despliegues de alta frecuencia podrían beneficiarse de cualquiera de los enfoques, dependiendo de tus requisitos específicos.
Conclusión#
GitOps proporciona un paradigma poderoso para gestionar tanto aplicaciones como infraestructura. Ya sea que elijas un enfoque basado en push o en pull, el principio central sigue siendo el mismo: Git como la única fuente de verdad.
Al adoptar prácticas de GitOps, obtenés mejor visibilidad, confiabilidad y gobernanza sobre tus despliegues. Como viste en la implementación de nuestro artículo anterior, también es posible crear herramientas GitOps personalizadas para cumplir con requisitos específicos.
Recordá que no hay una solución única para todos. El mejor enfoque depende de las necesidades de tu equipo, habilidades y restricciones organizacionales. Comenzá de a poco, aprendé de tus experiencias y adaptate a medida que avanzás.
Si querés aprender más sobre GitOps, te recomiendo leer esta página y experimentar vos mismo.
¡Espero que te haya gustado y te sea útil! ¡Hasta la próxima!
$ Comentarios
Online: 0Por favor inicie sesión para poder escribir comentarios.